說到pdf,那麼得刨根問底兒地問問為啥要有這種格式的文件?有word這樣格式的文件不夠使得嘛?先說個深有體會的事,平常有木有word在不同地方打開格式發生改變的苦惱?然而pdf就沒有這種麻煩。
當初Adobe公司設計PDF文件格式主要是要支持跨平臺,支持對網絡信息的發布。這種格式與平臺無關,那就是說PDF文件不管是在Windows,Unix還是在蘋果公司的Mac OS作業系統中都是通用的。這一特點使它成為在Internet上進行電子文檔發行和數位化信息傳播的理想文檔格式。
那pdf有這麼多優點為啥還要轉Word? 答:pdf不易編輯,不易排版,不易粘貼複製,在工作中要是在pdf裡面提取你想要的文字或者圖片,那可費事兒,對於文字要不就一個字一個字地比著打,要麼就充值某個軟體會員,開啟開掛模式。對於這兩個方法都不想用的小夥伴來說,教你們一個方法,可以有效提取出pdf裡面的文字並轉為word。
1.解析PDF庫pdfminer
說到從pdf中獲得想要的信息,那第一步就得解析出pdf裡面的東西,這裡就用到pdfminer庫,它完全專注於獲取和分析文本數據。PDFMiner允許人們獲取頁面中文本的確切位置,以及字體或線條等其他信息。它的好處也是大大的:
完全用Python編寫。各種字體類型(Type1,TrueType,Type3和CID)支持。PDF到HTML轉換(使用示例轉換器Web應用程式)。大綱(TOC)提取。等等好處,接下來在看看它處理pdf的流程是哪樣
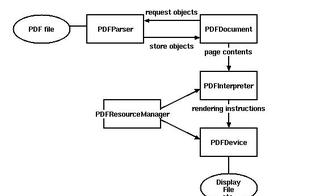 流程
流程這圖看起來太麻煩,簡單幾句話就是:
PDFParser 先從文件中提取數據,然後給PDFDocument類PDFDocument類將傳遞來數據傳給PDF解釋器PDFPageInterpreterPDFPageInterpreter去處理頁面內容PDFDevice將其轉換為我們所需要的內容PDFResourceManager,PDF資源管理器用於保存共享內容例如字體或圖片。2.pdf轉word實操
pdfminer的流程簡單了解了一下,那具體怎麼用,來一步步走
1.既然要先用PDFParser 先從文件中提取數據,然後給PDFDocument類,那麼就需要有PDFParser 和PDFDocument兩個類,並需要讓兩者關聯起來。
2.接下來創建PDFPageInterpreter,它的參數需要傳入PDF資源管理器PDFResourceManager和PDF的設備對象device。
3.解釋器創建好後,用解釋器調用process_page方法,去解析頁面。然後設備對象調用get_result()方法得到這個頁面的LIPage對象
4.在LIPage對象中有LTImage圖片對象,LTCurve曲線對象,LTFigure figure對象,LTTextBoxHorizontal文本對象。這裡我們只要LTTextBoxHorizontal對象,所以遍歷LIPage在裡面得到LTTextBoxHorizontal對象,獲取裡面的文字內容。
5.將得到的文字內容寫入到word文件中。
6.來看看效果咋樣
 要用的PDF(只截取了一部分)
要用的PDF(只截取了一部分) 生成的word(截取的一部分)
生成的word(截取的一部分)可以看到轉化的效果還是很不錯的,只是格式稍微有點亂。
當處理多個pdf時,可以採用多線程處理。這裡pdf轉word只提供一個簡單的思路,當pdf裡面含有圖片,圖表就需要做另外的處理哦。